![]() We live in the age of data. Everywhere around us, we see very interesting sources of data being used in some very innovative uses. For example, Facebook uses our browsing history and search patterns to come up with sponsored posts. Imagine searching about the perks of using a Visa credit card over an American Express credit card. Then next moment, you decide to scroll Facebook, and the first sponsored post is an offer for a Visa Credit Card by a bank. Coincidence? A similar example is that of Gmail. If a mail has any word related to attachment, and the mail does not have any attachments, then Gmail prompts the user to double check if they have attached something or not. But that is a trivial example. At present, mail software companies are working on projects of auto replies or slang recognition. Slang recognition will identify obscene words or rough language, and give a sender a cool down time before allowing the sender to send the email. These are all examples of platforms using massive amounts of textual data or browsing information to identify patterns, and then using patterns to come up with predictions. Although these examples are set in an international stage, the case of Bangladesh should not be forgotten as well.
We live in the age of data. Everywhere around us, we see very interesting sources of data being used in some very innovative uses. For example, Facebook uses our browsing history and search patterns to come up with sponsored posts. Imagine searching about the perks of using a Visa credit card over an American Express credit card. Then next moment, you decide to scroll Facebook, and the first sponsored post is an offer for a Visa Credit Card by a bank. Coincidence? A similar example is that of Gmail. If a mail has any word related to attachment, and the mail does not have any attachments, then Gmail prompts the user to double check if they have attached something or not. But that is a trivial example. At present, mail software companies are working on projects of auto replies or slang recognition. Slang recognition will identify obscene words or rough language, and give a sender a cool down time before allowing the sender to send the email. These are all examples of platforms using massive amounts of textual data or browsing information to identify patterns, and then using patterns to come up with predictions. Although these examples are set in an international stage, the case of Bangladesh should not be forgotten as well.
 There is a common myth that data in Bangladesh is rare. The truth is much different. Sources of data abound in our fast-developing landscape, one just has to look at the right places. Traditional sources of data were always there - CIA world factbook, World Bank and IMF economic data, Bangladesh Bureau of Statistics data, trade data from US Embassy Dhaka, and many other sources, where one can get any data ranging from demographics to trade flows to economic indicators. New areas of data are springing up as well. E-commerce is on the steady rise in Bangladesh, and many companies are now opting for both digital presence and facilities to trade online. This leads to a veritable source of steady flow of data. For example, a single transaction can give the website data on the location where the website was logged in, the device, the screen resolution of the device, the operating system, the merchandise that has been bought, the quantity, the gender of the buyer, the age, address, regular transaction patterns and countless other information. Imagine what can be done with that! Other than that, thanks to digitisation, information on traffic flows, flow of raw materials and agricultural produce from ports to cities, consumer sentiment on marketing and social campaigns, opinions of the society in general, are information that are easily traceable and are being collected in regular intervals, not only in multinational companies in Bangladesh, but also in local conglomerates. But that is not all - companies like LightCastle Partners and Nielsen Bangladesh are actively collecting data for market research and social research. This is leading to large datasets being created, which have rich data on the local markets. A few other large organisations have been collecting data for a very long time, just because they were required to as per regulations or international quality certifications. The banking industry is one of the torchbearers in accumulating large repositories of data in Bangladesh.
There is a common myth that data in Bangladesh is rare. The truth is much different. Sources of data abound in our fast-developing landscape, one just has to look at the right places. Traditional sources of data were always there - CIA world factbook, World Bank and IMF economic data, Bangladesh Bureau of Statistics data, trade data from US Embassy Dhaka, and many other sources, where one can get any data ranging from demographics to trade flows to economic indicators. New areas of data are springing up as well. E-commerce is on the steady rise in Bangladesh, and many companies are now opting for both digital presence and facilities to trade online. This leads to a veritable source of steady flow of data. For example, a single transaction can give the website data on the location where the website was logged in, the device, the screen resolution of the device, the operating system, the merchandise that has been bought, the quantity, the gender of the buyer, the age, address, regular transaction patterns and countless other information. Imagine what can be done with that! Other than that, thanks to digitisation, information on traffic flows, flow of raw materials and agricultural produce from ports to cities, consumer sentiment on marketing and social campaigns, opinions of the society in general, are information that are easily traceable and are being collected in regular intervals, not only in multinational companies in Bangladesh, but also in local conglomerates. But that is not all - companies like LightCastle Partners and Nielsen Bangladesh are actively collecting data for market research and social research. This is leading to large datasets being created, which have rich data on the local markets. A few other large organisations have been collecting data for a very long time, just because they were required to as per regulations or international quality certifications. The banking industry is one of the torchbearers in accumulating large repositories of data in Bangladesh.
Sometimes data is not readily available, which is where comes two very interesting methods that are revolutionising big data scene globally. The first method is that of Web Harvesting. The term itself is very interesting, suggesting that people "Harvest" the Web. But what is there to harvest? Let's look at an example. One of the crucial pieces of information of purchasing any unknown product from online stores is to read the customer reviews. If someone is interested to know what people are talking about a product, the rating that the product gets and the price of the product, it's all available in the product description page of the website. Getting such information for say about 500 products would need going through 500 different pages, and copying information from different sections of these pages. If the task gets bigger, such getting information about 5,000 products, the task of clicking through all the 5000 different product pages will turn out to be a very boring and tedious job. But "Web Harvesting" makes the whole job a lot easier. Using coding languages such as Python, one can first load a page, and can read the HTML code (the coding used to make the website), pinpoint the information necessary, and then save it in an excel file. It gets better! If one can do that for a page, the next step will be repeating the process for each different product, where the code just needs to rotate through each page using the unique product code or page identifying number, or even page number. If this coding can be automated for 10 products, the same can be done for 500, 5000 or even 50,000. Sky is the limit here!
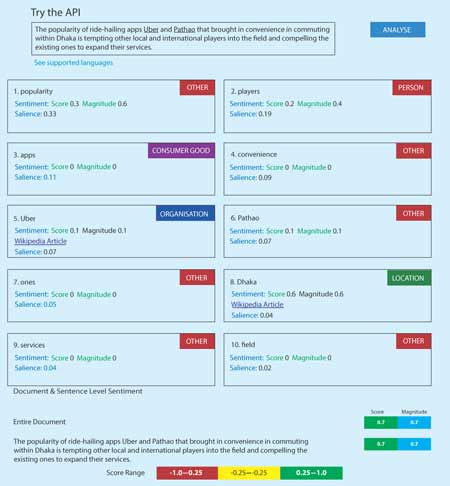
Another interesting method is the through the usage of APIs - Application Programming Interface. Suppose a company wants to know the ideal location of a store, and it has six possible choices. All the information of the supplying warehouses and potential markets are available to them. Also suppose that this is a fast food shop (something we all can relate to), and the popularity of the place is very important factor. One way to find out how much time and distance supplies and people must travel to the location can be obtained simple searches on google maps. But if the number of location options becomes 60, then these searches again become tedious. Google Maps offer something called a Distance Matrix API, which allows users to get all the distance and travel times using just one code. And that is not all. Users can have all the locations stored in a spreadsheet file, and from a certain destination, they can calculate all the individual distances, shortest routes, times, traffic information, travel time using buses or using cars etc. Again, that is still not the limit. The business can also use Instagram API, which will show all the public posts and pictures taken in those locations, based on their latitude and longitude. Too much? Not yet! Using Twitter API and third-party news API, one can pull up all the major headlines in those locations, and the twitter posts related to those locations. And who has the time to read all the opinions, posts and headlines? Google Natural Language Processing API offers something called sentiment and keyword analysis. Using machine learning algorithms, this API can read a sentence and tell the user whether the sentence had a positive or a negative sentiment, what were the keywords mentioned in the sentence, and type of keywords they are (i.e. location, person, product) and if they have any Wikipedia article, link to that article! The following set of illustrations shows this:
Although these might sound a bit far-fetched, these are happening right now, and even in Bangladesh. The article named "Demystifying big data analytics" by the same author already highlights the basic coding skills that can be developed, and this requires minimal previous coding background.
This article was aimed to rebuff the data scarcity myth, illustrating some interesting sources of data, even for our country, and giving an idea of some very interesting uses of these data. The only question that remains is "What's stopping us to make use of such data to come up with our answers to a more successful business and a better society?".
The writer is a lecturer of Applied Statistics and Decision Support Systems at North South University. saqiful@gmail.com
© 2026 - All Rights with The Financial Express